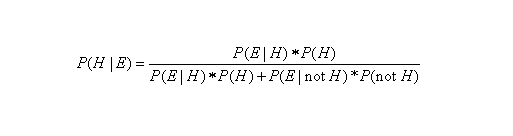Note (1/4): The second half of this post has been significantly revised.
We have been highlighting some of the main ideas contained in Tetlock and Gardner’s 2015 “superforecasting” book in our previous two blog posts. Yesterday, for example, I presented a step-by-step overview of their Bayesian approach to forecasting. In my next two posts, I will restate Tetlock and Gardner’s Bayesian methodology in formal mathematical notation (see image below) and present a concrete example relevant to my domain of expertise (constitutional law).
In particular, I would love to be able to forecast when the Supreme Court of the United States (SCOTUS) is going to overturn a precedent or when it is going to declare a law unconstitutional. In order to engage in Bayesian reasoning in this domain, i.e. in order to make a Bayesian forecast, we will need three pieces of information: (1) the “base rate” or the historical frequency p(H) in which precedents have been overturned in the past or in which federal laws have previously been declared unconstitutional; (2) some piece of evidence E, such as a large number of amicus briefs submitted to SCOTUS, that we are likely to see when a law or precedent is destined to be overturned, or p(E|H); and last but not least, (3) the probability or likelihood of seeing this same piece of evidence, i.e. a large number of amicus briefs, in those cases in which a precedent is upheld, or p(E|not H).
(Before proceeding, you should be asking, Why should the number of amicus briefs be considered a relevant piece of evidence when we are engaged in judicial forecasting? In brief (pun intended), it turns out there is a large scholarly literature attempting to measure the influence of amicus briefs on judicial decision making. I will review this fascinating literature in a separate post. For now, however, the fact that such an amicus practice exists and that there is such a large literature about this practice are, by themselves, relevant pieces of evidence that amicus briefs are important.)
How would we begin to engage in Bayesian reasoning in this domain? First, let’s start with the base rate. Since SCOTUS was created in 1789, it has heard over 28,000 cases! (Today, SCOTUS hears about 80 cases per term, with each Supreme Court Term commencing on the first Monday of October and concluding on the last week of June.) During this 230-year span, SCOTUS has overruled itself 236 times (here is a comprehensive list of “Supreme Court decisions overruled by subsequent decision“) and has found 182 federal laws to be unconstitutional (here is a list of “Acts of Congress held unconstitutional in whole or in part by SCOTUS“). These initial observations thus appear to indicate an extremely low base rate of 0.015 (rounded up), or 236 + 182 = 418 divided by 28,000.
Next, since the use of amicus briefs has become a regular practice only recently, let’s tinker with our historical base rate to make it more accurate. Specifically, let’s consider limiting our evidence to the recent past, say the period from the 2005-06 Term, when John Roberts replaced the late William Rehnquist as Chief Justice of SCOTUS, to the end of the 2017-18 term last year. (By 2005, the practice of amicus briefs in SCOTUS had become quite common.) During this shorter span of time (2005 to 2018), SCOTUS heard about 1000 cases, and by my count, the Roberts Court has decided 13 cases in which it overruled one or more of its precedents and has struck down 26 federal laws, either in whole or in part, or an average of two federal laws struck down per year. (Shout out to Professor Jonathan H. Adler for compiling these data!) These observations give us a revised base rate of 0.04, or 40 divided by 1000–still small, but almost three times as large as our previous base rate.
Notice that the base rate, standing alone, indicates that the reversal of a precedent or a judicial declaration that a law is unconstitutional is an extremely rare event, but its probability is not zero. In fact, the base rate could even be higher, since we should exclude the vast majority of cases in which none of the parties are asking SCOTUS to change the jurisprudential status quo. After all, asking SCOTUS to take such dramatic action as overruling a precedent or striking down a federal law is a long shot. Given this reality of appellate practice, let’s assume that the parties have asked SCOTUS to change the status quo in only 100 of the 1000 cases SCOTUS has heard from 2005 to 2018. (Note: this is just a simplifying assumption on my part. I intend on applying for a research grant to actually count up the number of times since 1789 that a lawyer has requested SCOTUS to change the jurisprudential status quo.)
This simplifying assumption will thus cause our revised base rate to increase up to 40 percent (!), or 0.4 (40 divided 100). This increase makes sense, since we have narrowed down the base rate to the smaller subset of cases in which one of the parties is asking SCOTUS to change the status quo by overruling a precedent or by striking down a federal law. But at the same time, the base rate is too high because it lumps together two types of cases: (1) cases in which a precedent is overruled, and (2) cases in which a federal law is declared unconstitutional. For the remainder of this post, let’s focus on the first type of case only. (Full disclosure: the stability of SCOTUS’s precedents is what motivated to engage in this research in the first place.)
Since there are only 13 Roberts Court cases in which a precedent was overruled, our revised base rate is 0.13, or 13 divided by 100. Now that we have a plausible base rate, we must next proceed to revise or “update” our historical base rate upon the arrival of new evidence. When SCOTUS agrees to hear a new case, for example, many government agencies, interest groups, and other non-parties will have an opportunity to present amicus briefs to the Court. In fact, it turns out that the median or average number of amicus briefs submitted to SCOTUS since 2010 is about 11.75 per case (see here, for example), but we should expect a greater number of amicus briefs the more important the case, i.e. the more likely the case has national or even international implications. In my next post, we will use this information (the number of amicus briefs) to predict the posterior probability that a precedent will be overturned.